Touring the Coco Sandbox Dataset
In this tutorial, you will see some cool features of Encord Active based on the Coco sandbox dataset. You will go through the following steps:
This tutorial assumes that you have installed encord-active.
1. Downloading the dataset
Download the data by running this command
$ encord-active download
The script will ask you to choose a project, navigate the options with ↑ and ↓ and hit enter.
Now encord-active will download your data.
2. Opening Encord Active in your browser
When the download process is done, encord-active will print how to run the app:
cd /path/to/downloaded/project
encord-active start
If the command hangs and nothing happens in your browser, go to http://localhost:8501.
3. Finding and flagging label errors
You will carry out this process in two steps.
Identifying metrics with label errors
When you open Encord Active, you should see a page like this
Expand the "Label Quality" tab in the left sidebar and click the "Summary" page. The page should look like this:
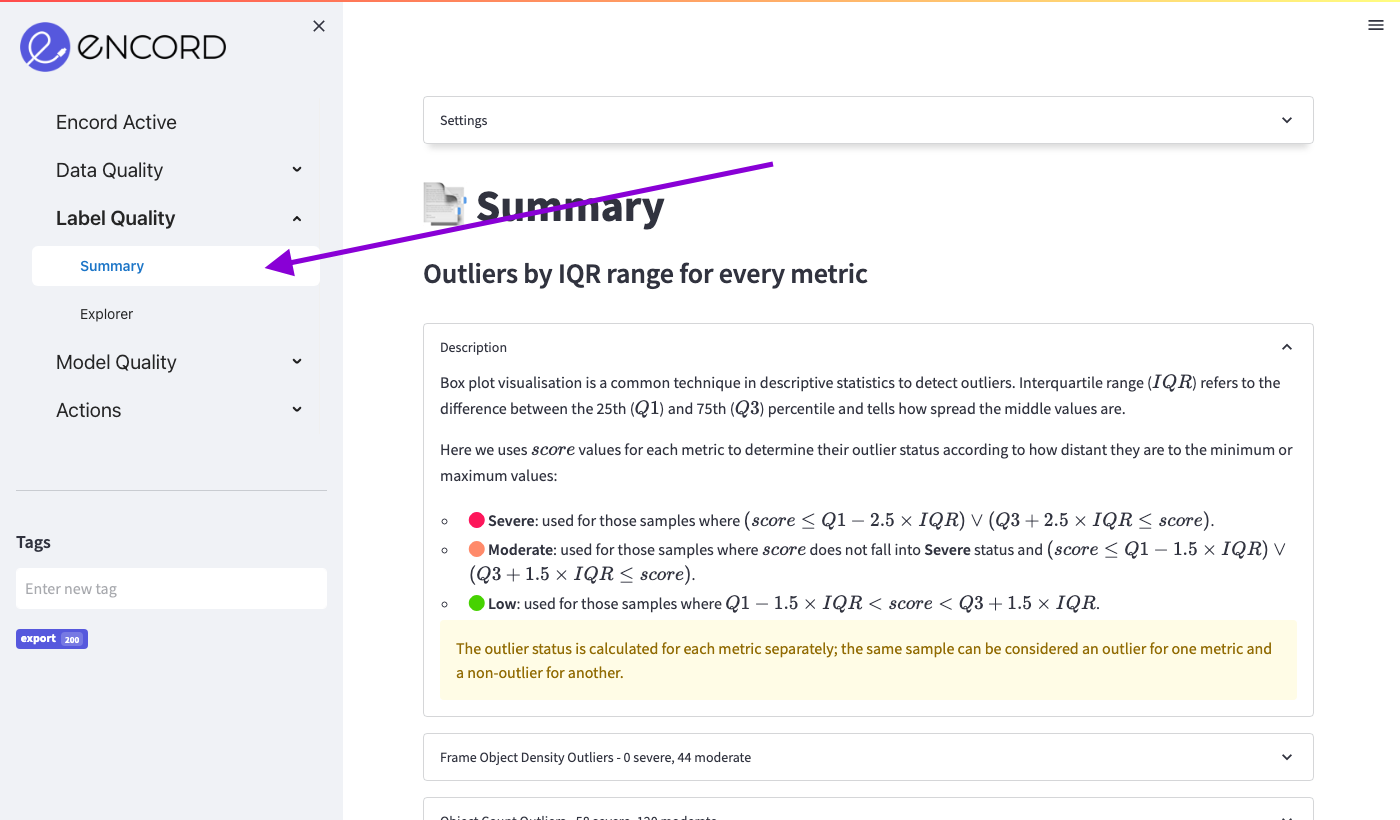
In the summary page, you will find all the outliers that Encord Active automatically found based on all the metrics that were computed for the labels.
Scroll down on the main view and expand the "Annotation Duplicates Outliers" section and expand it. The page should look similar to this:
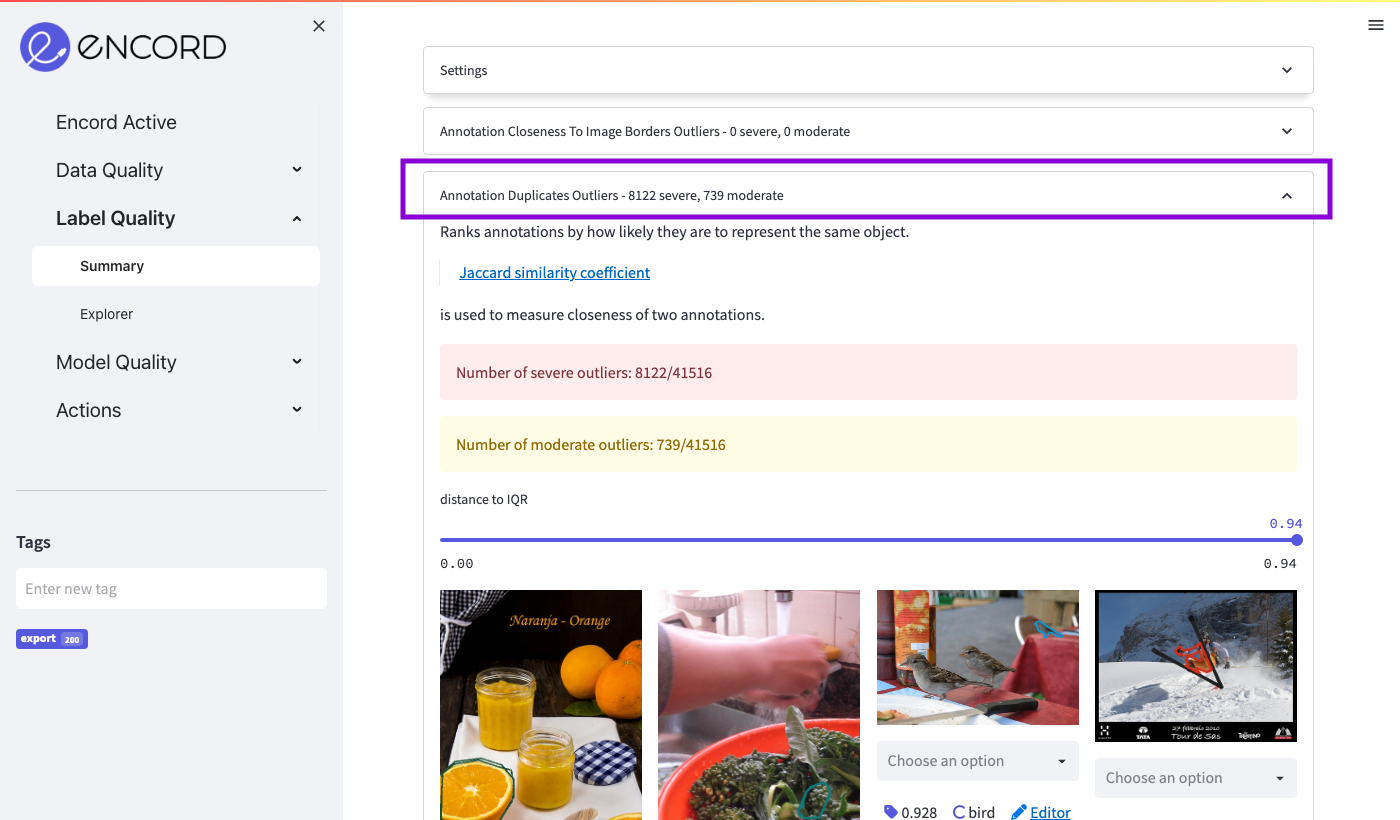
The page will show you how this metric was computed, how many outliers were found and some of the most severe outliers.
If you hover the image with the oranges, you can click the expand button as indicated here:
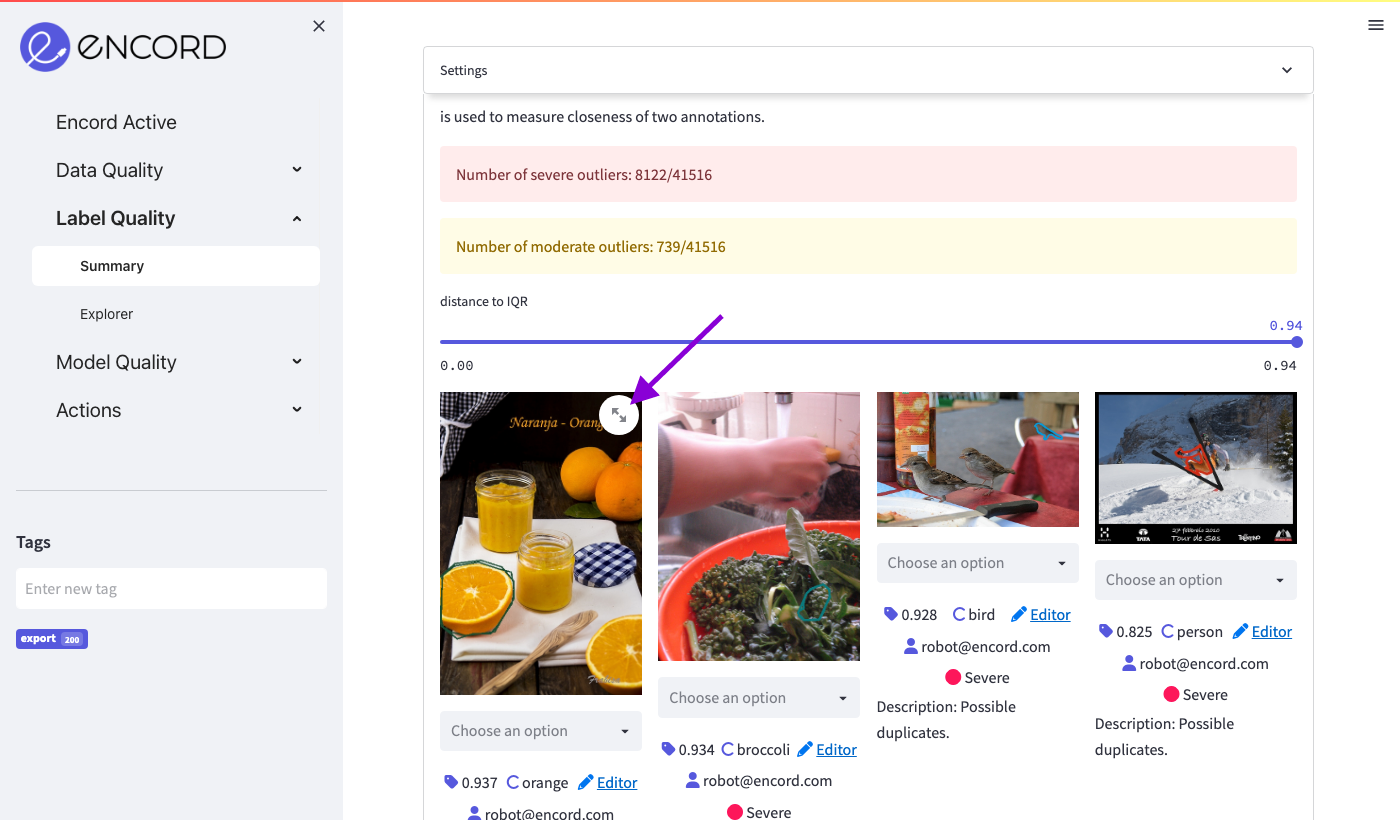
When clicking the button and taking a closer look at the image, you will see that there are two overlapping annotations on the orange.

Notice the duplicated annotations.
Hit esc to exit the full screen view.
If you take a closer look at the annotations in the other displayed images, you will notice the same issue.



You can find other sources of label errors by inspecting the other tabs. Good places to start could be the "Object Area" and "Object Aspect Ratio" sections in the App.
Tagging label errors
To tag the images with the identified label errors, you first add a new tag by typing in the tag name in the left sidebar and hitting enter.
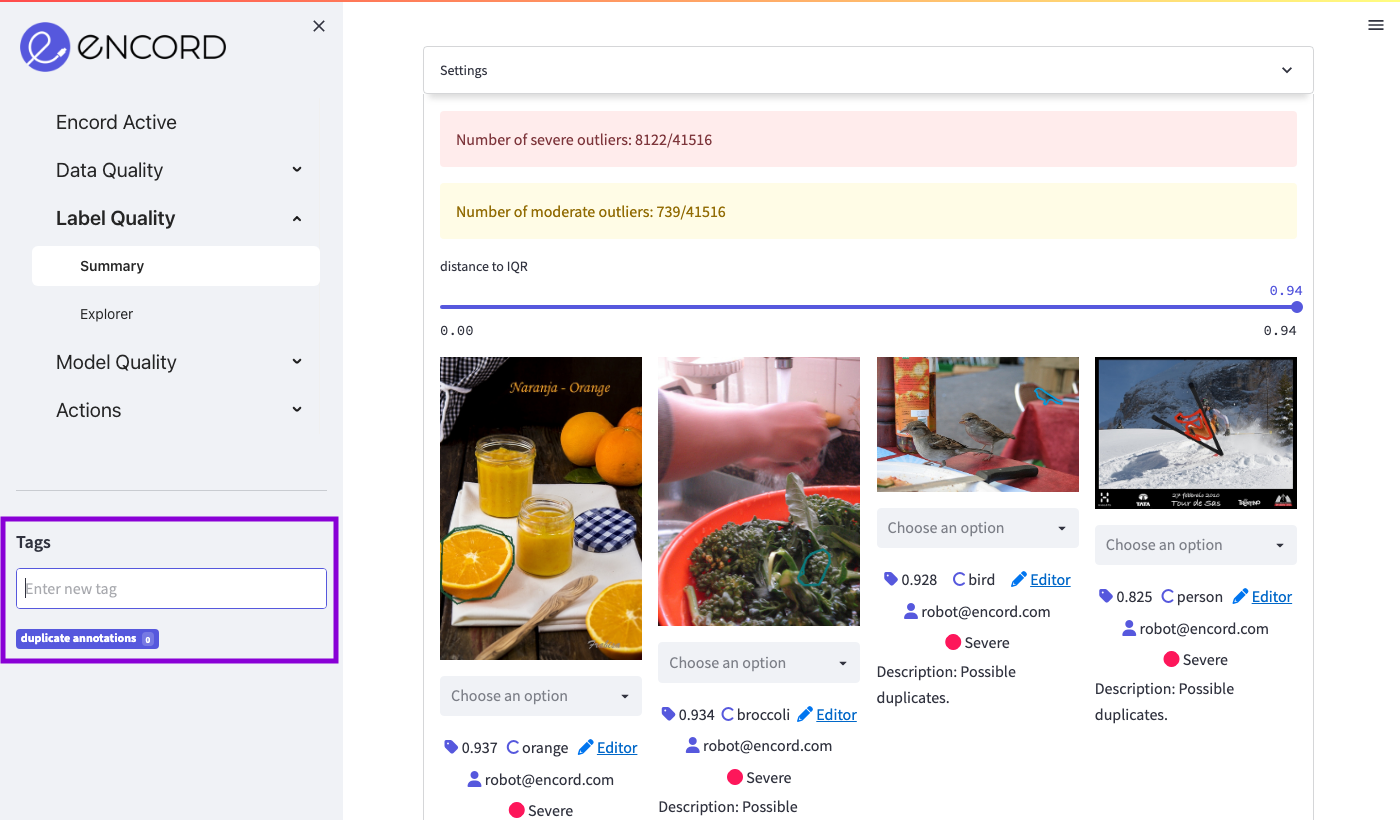
Afterwards, you can add the tag to the images you see in the outlier pane by selecting the tag from the drop-down below each image:
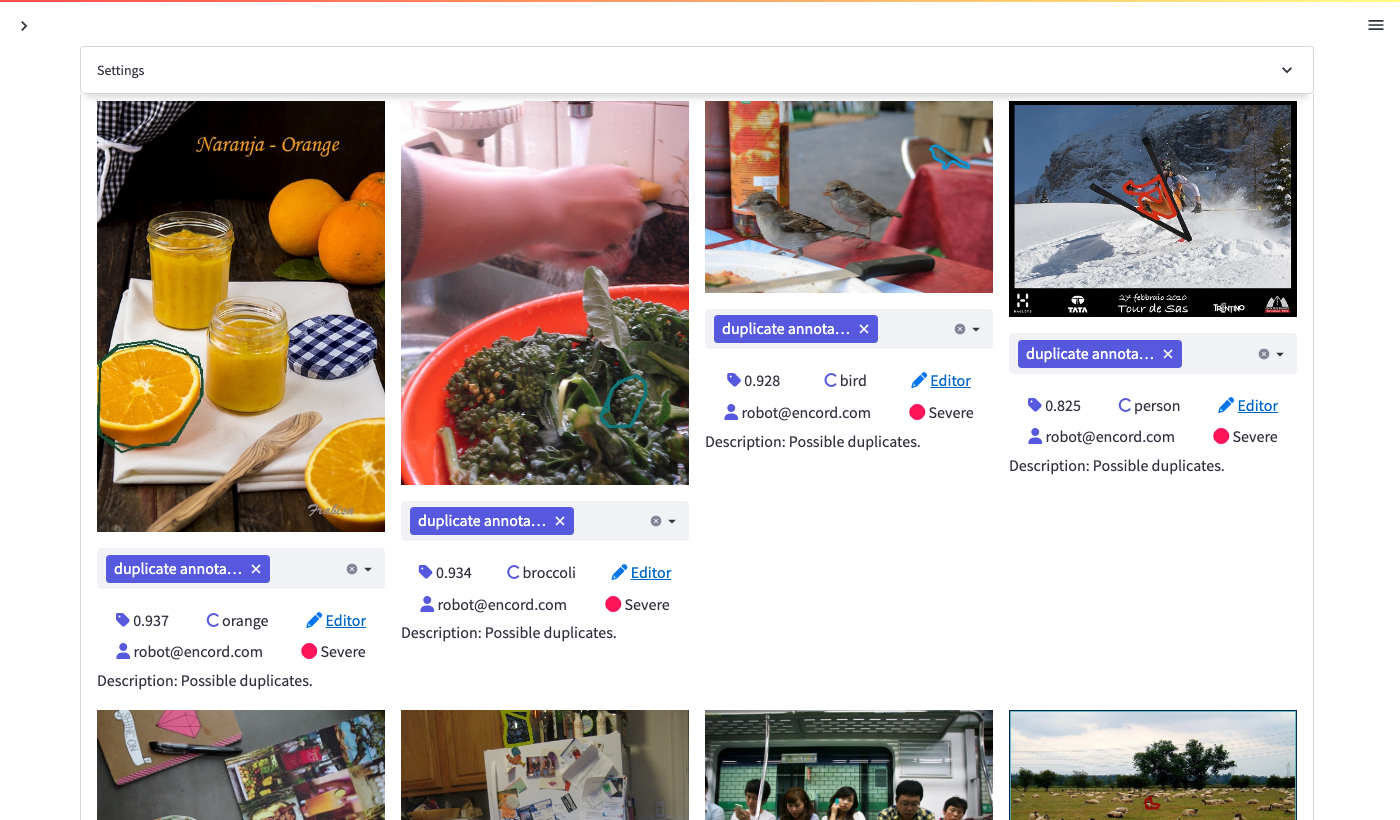
Exporting labels for re-labeling
Suppose you have now tagged all the duplicated annotations that you would like to export for re-labeling. Then, you go to the Actions -> Filter & Export tab in the left sidebar and filter by the tag that you created (as indicated by the purple arrows).
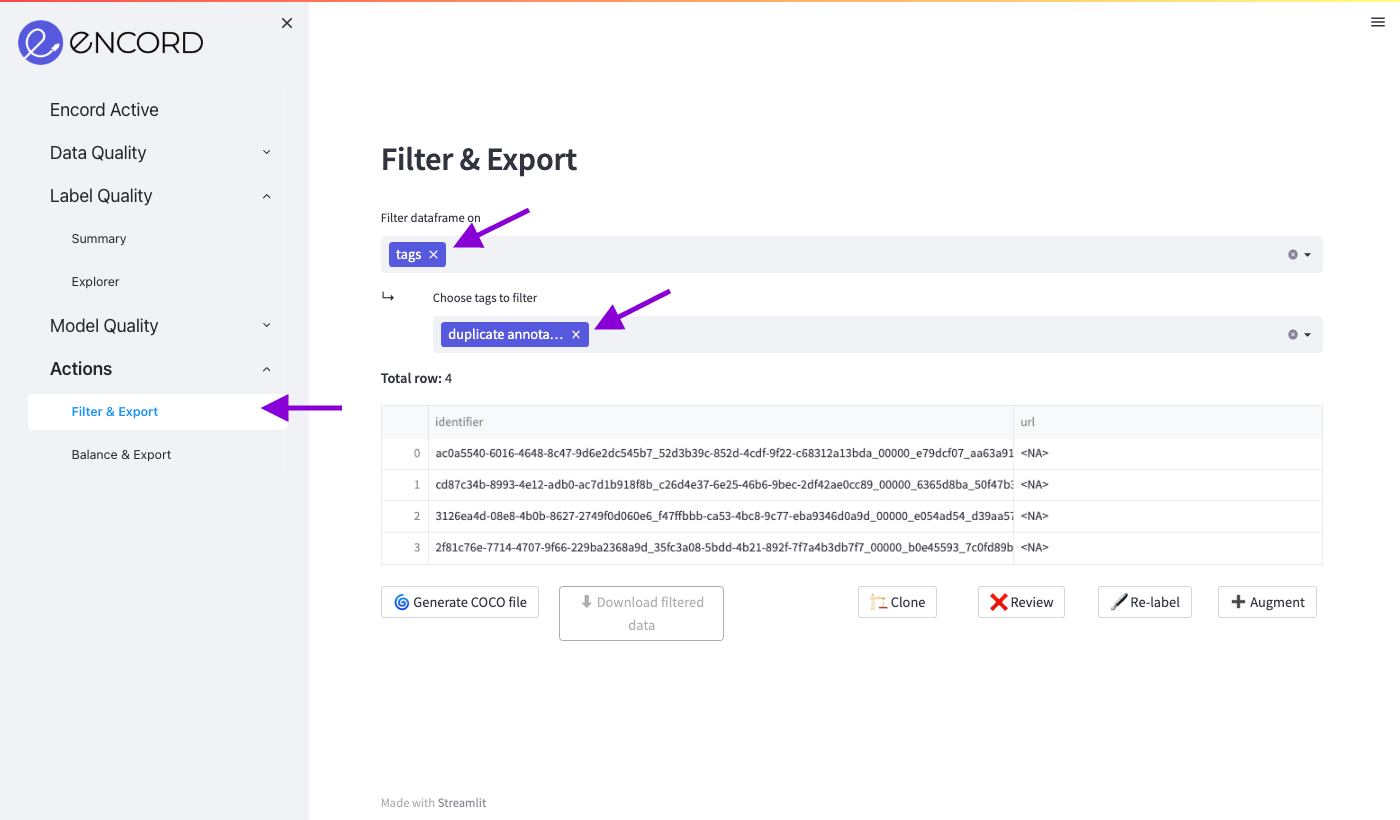
Note how your data has been filtered to only the rows that you tagged.
Now you can Generate COCO file, Clone the data into a new Encord project, or send the data for Review, Re-label, or Augmentation tasks.
4. Figuring out what metrics influence model performance
Encord Active also allows you to figure out which metrics influence your model performance the most. In this section, we'll go through a subset of those:
The high level view of model performance
mAP and mAR scores
First, navigate to the Model Quality > Metrics page to find sections that automatically give you multiple insights into your model performance.
The first section will give you the mean Average Precision (mAP) and the mean Average Recall (mAR) of your model based on the IOU threshold set in the top of the page.
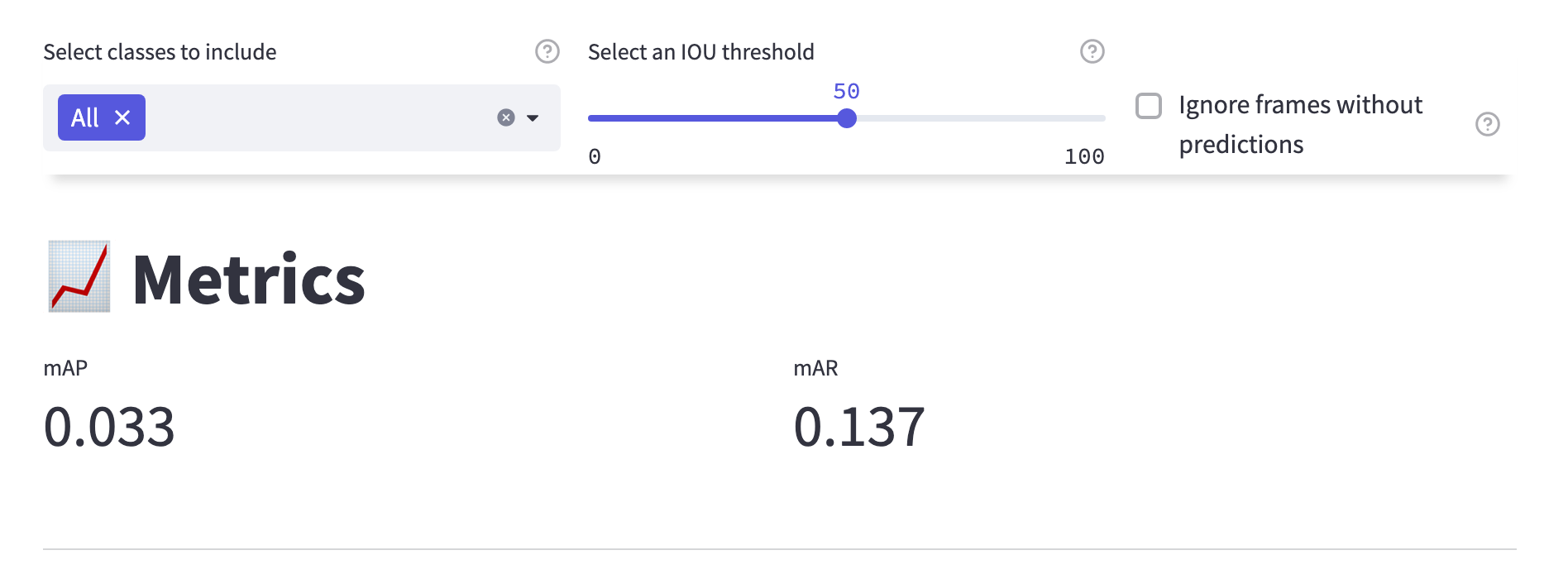
If you drag the slider, you will notice how the score changes. You can also choose to see the aggregate score for certain classes by selecting them in the drop-down to the left.
Metric importance and correlation
In the next section (the Metric Importance), you will find importances and correlations of your model performance as function of metrics.
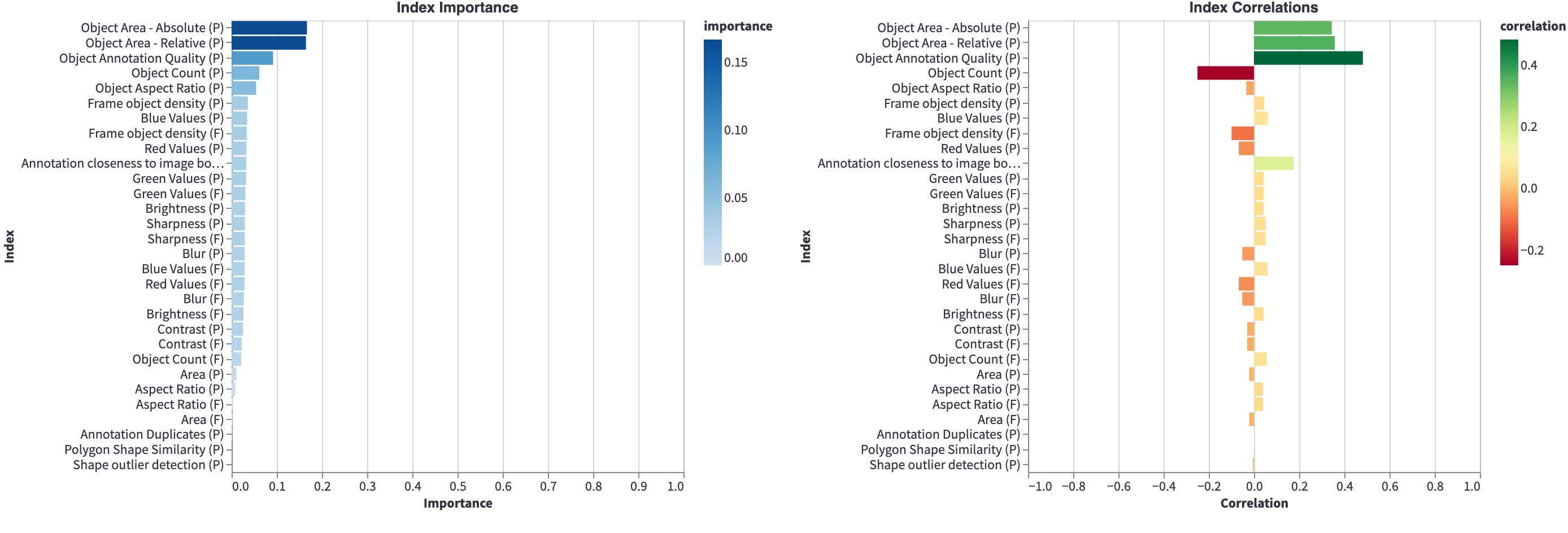
From this section, you quickly find that, e.g., "Object Area - Relative (P)" has a high importance for the model performance.
The "(P)" and the "(F)" in the labels of the plots indicate whether the metric was run on predictions or frames, respectively.
A next step from here would be to jump to the Performance by Metric page and have a look at exactly how the true-positive rate of the model is affected by this metric. However, we want to show you the rest of this page prior to doing this. You can skip straight ahead to the Inspecting Model Performance for a Specific Metric if you are too curious to wait.
Subset scores
Before jumping into specific metrics, we want to show you the decomposition of the model performance based on individual classes. If you look in the Subset selection scores section, you will find the average precision (AP) and average recall (AR) scores for each individual class.
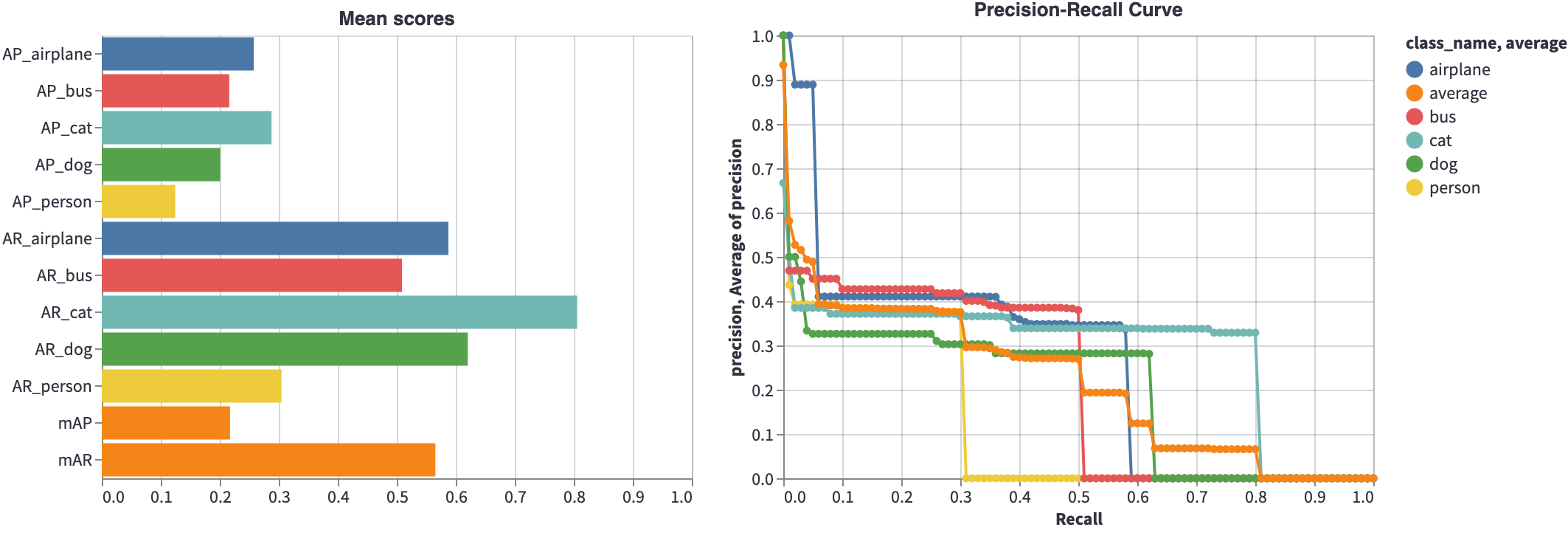
We've choosen a subset of classes [airplane, bus, cat, dog, person] in the settings in the top of the page to make the plots more digestible.
From the left plot (Mean scores), we can see the AP and the AR for each individual class.
The right plot shows the precision-recall curves for each of the classes.
From these plots, we learn that the model performs better on the cat class than it does on, e.g., the person class.
To learn for which instances the model works and for which it doesn't, you can look in the True Positives, False Positives, and False Negatives tabs to see concrete instances of the three success/failure modes.
Inspecting model performance for a specific metric
Above, we noticed that the "Object Area - Relative (P)" metric has a high importance on the model performance. To learn more about how the specific metric affects the model performance you:
- Click the Performance By Metric tab in the sidebar.
- Select the "Object Area - Relative (P)" metric in the settings in the top.
You should now see a page similar to this:
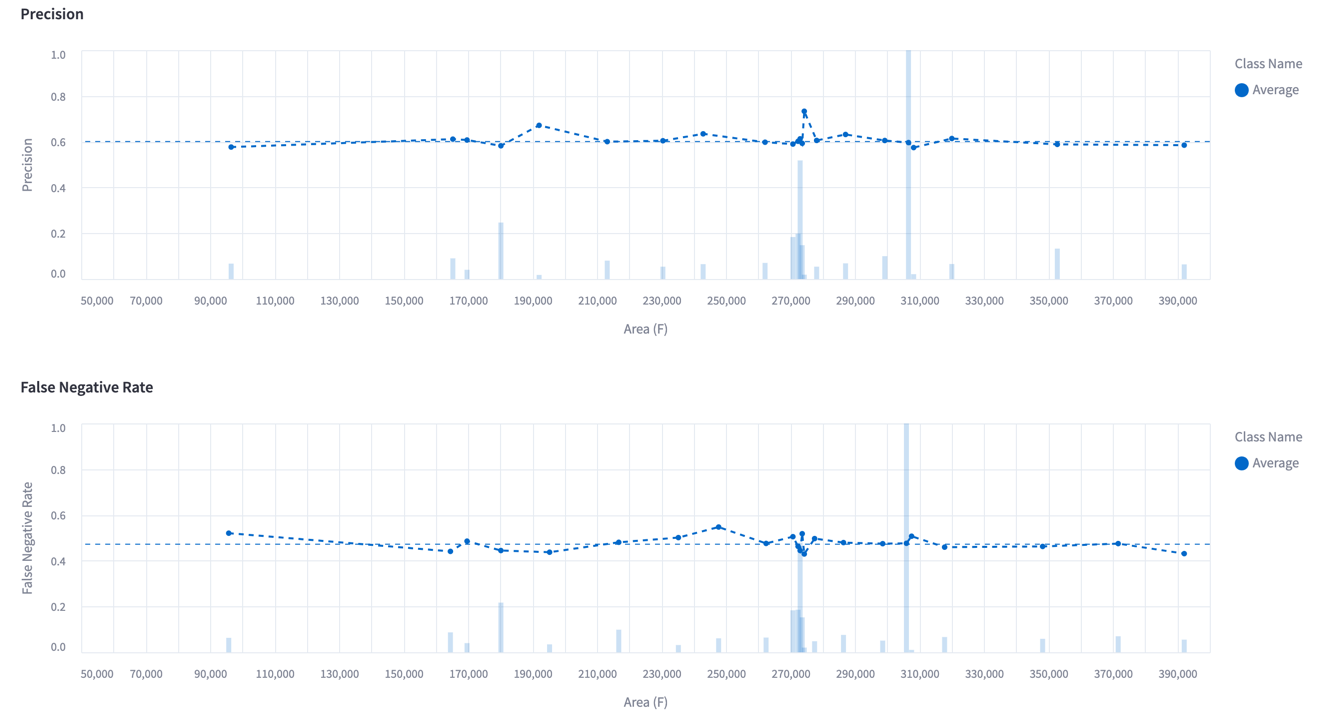
The plot shows the precision and the false negative rate as a function of the selected metric; the "Object Area - Relative (P)" in this case. We can see how when the model predictions are small in terms of the absolute area, then the precision is low (bad), while larger predictions are more often correct (good). Similarly, when labels are small, the false negative rate is high (bad), while larger labels are less likely to be issued by the model (good).
5. Summary
This concludes the tour around Encord Active with the COCO Sandbox dataset. By now, you should have a good idea about how you can improve both your data, labels, and models by the insights you get from Encord Active.
Next steps
- We've only covered each page in the app briefly in this tutorial.
- To learn more about concrete actionable steps you can take to improve your model performance, we suggest that you have a look at the Workflow section.
- If you want to learn more about the existing metrics or want to build your own metric function, the Quality Metrics section is where you should continue reading.
- Finally, we have also included some in-depth descriptions the Command Line Interface.